TORQ SDK 介绍
TORQ 简介
TORQ (Tensor-Optimized Runtime for Quantization) 可以帮助用户快速进行 AI 模型转换、推理和性能评估,将 AI 模型部署到知合计算系列芯片。
支持硬件平台
TORQ 适用如下硬件平台:
| 支持硬件平台 |
|---|
| A200 |
| A210 |
TORQ 工具链介绍
TORQ 工具链总体工作流程如下。
-
运行 TORQ-Toolkit 工具,将训练好的模型转换为 TORQ 模型。
-
使用 TORQ C API 将 TORQ 模型部署在开发板上。
软件栈整体的框架如下:
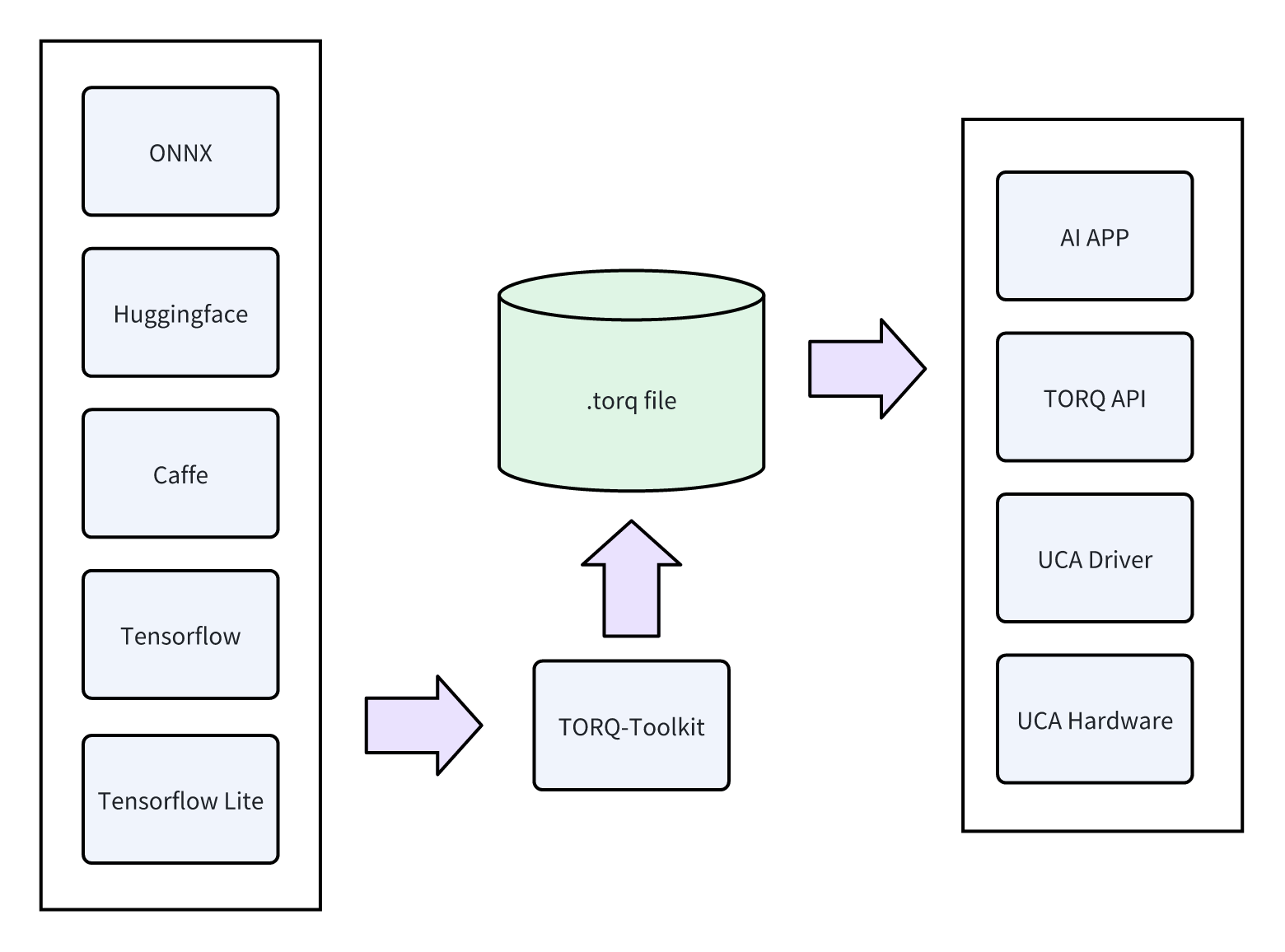
TORQ-Toolkit 功能介绍
TORQ-Toolkit 是为用户提供在计算机上进行模型转换、推理和性能评估的开发套件。TORQ-Toolkit 的主要功能框图如下。
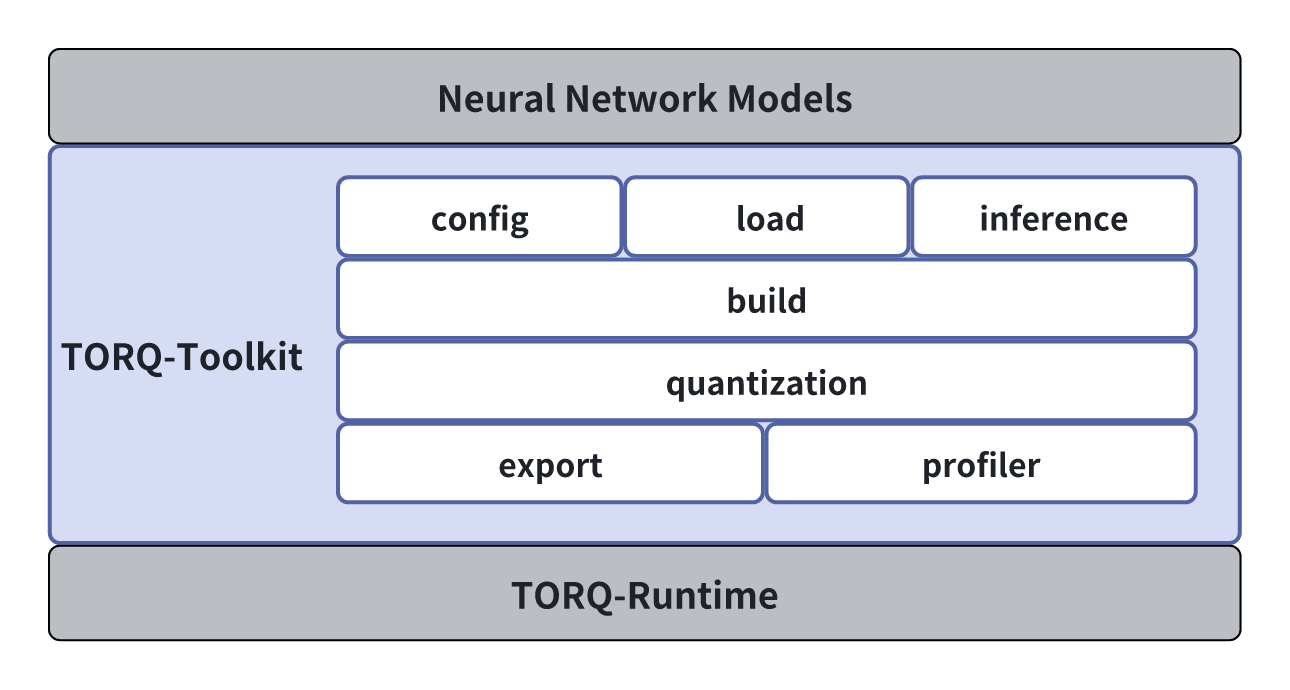
通过该工具提供的 Python 接口可以便捷地完成以下功能:
-
模型转换。
支持将 ONNX、TensorFlow、TensorFlow Lite、Caffe 等模型直接转换为 TORQ 模型。 其他框架(如 PyTorch)可先导出为 ONNX 格式,再进行 TORQ 模型转换。
-
量化功能。
支持将浮点模型量化为定点模型。
-
模型推理。
-
将 TORQ 模型分发到指定的 NPU 设备上进行推理并获取推理结果。
-
在计算机上仿真 NPU 运行 TORQ 模型并获取推理结果。
-
-
性能和内存评估。
将 TORQ 模型在模拟器上运行,以评估模型在实际设备上运行时的性能和内存占用情况。
TORQ Runtime 功能介绍
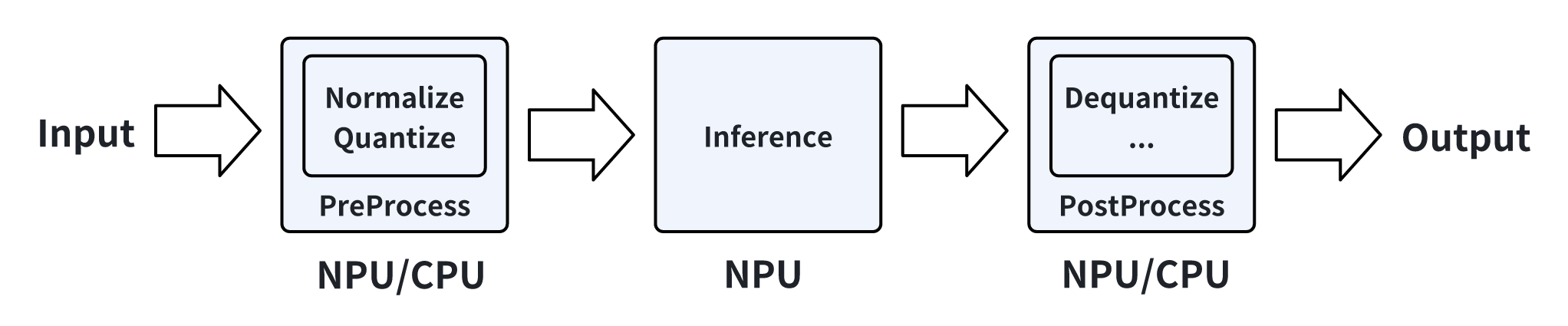
TORQ Runtime 负责加载 TORQ 模型,并调用 NPU 驱动实现在 NPU上推理 TORQ 模型。推理 TORQ 模型包括原始数据输入预处理、NPU 运行模型、输出后处理三项流程。
根据不同模型输入格式和量化方式, TORQ Runtime 提供通用 API 和零拷贝 API 两种处理流程。
说明
- 当用户输入数据只有虚拟地址时,只能使��用通用 API 接口。
- 当用户输入数据有物理地址或 fd 时,两组接口都可以使用。
-
通用 API 推理:推理简洁、无门槛,易于使用。
-
数据的归一化、量化、数据排布格式转换、反量化等在 CPU 上运行。
-
模型本身的推理在 NPU 上运行。
-
-
零拷贝 API 推理:对输入数据流程处理效率比通用 API 高。
零拷贝 API 支持数据在不同的 IP 核之间流动,没有数据拷贝,以减少 CPU 及 DDR 带宽消耗。零拷贝API支持直接将camera 或者解码出来的数据导入到 NPU 中使用。
-
归一化、量化和模型推理在 NPU 上运行。
-
NPU 输出的数据排布格式和反量化过程在 CPU 或者 NPU 上运行。
-
TORQ 开发流程介绍
完整的 TORQ 开发流程可确保人工智能模型能够成功转换、评估,最终在 UCA 上高效部署。具体开发流程如下图。

-
模型转换:原始深度学习模型转化为 TORQ 格式,后续在 UCA 平台上推理。
a. 获取原始模型。
获取或训练深度学习模型。�建议使用 ONNX 或 TensorFlow 主流框架。
b. 模型配置。
配置归一化参数、量化参数和目标平台等参数。
c. 模型加载。
根据模型框架选择加载接口将模型导入 TORQ-Toolkit。
d. 模型构建。
torq.build()接口构建 TORQ 模型。e. 模型导出。
torq.export_torq()接口将 TORQ 模型导出成目录(.torq 后缀),用于后续部署。 -
模型评估:评估模型推理结果的推理性能和内存占用等关键指标。
-
性能评估:
torq.eval_perf()接口分析模型在 UCA 平台上的算力需求,提升推理性能。 -
内存评估:
torq.eval_memory()接口了解模型在 UCA 平台上的内存使用情况,最小化内存占用。
-
-
板端部署运行:模型的实际部署和运行。
a. 模型初始化:加载 TORQ 模型到 UCA 平台。
b. 模型前处理:加载待推理数据到 UCA 平台。
c. 模型推理:输入数据传递给模型并获取推理结果。
d. 模型后处理:获取推理结果进行后处理,并传给应用端。
e. 模型释放:在完成推理流程后,释放模型资源。
缩略词和术语
| 术语/缩略词 | 说明 |
|---|---|
| TORQ 模型 | 知合系列芯片专用的神经网络模型格式,后缀名为 .torq,用于在知合NPU高效运行AI推理任务,方便用户开发AI产品。 |
| UCA | 全称 Unify Computer Architecture,知合多媒体 HAL 层接口。 |
| NATIVE_LAYOUT | 指对于 NPU 运行�时而言,通常性能表现最佳的内存排列格式。 |
| tensor | 张量。在深度学习中,为高阶数组的数据,用于表示不同维度的数据。 |
| fd | 文件描述符,被用来标识一块内存空间。 |
开发环境准备
关于 TORQ-Toolkit 的安装方式和设备端 NPU 环境准备,请参考 TORQ-Toolkit 快速上手。
TORQ 使用说明
模型转换
在模型转换环节,用户可以使用不同框架的深度学习模型训练或获取预训练模型,并转换为 TORQ 格式,以便在 UCA 上部署和推理。
这些接口涵盖了 TORQ-Toolkit 模型转换阶段,根据不同的需求和应用场景,用户可以选择不同的模型配置和量化算法进行自定义设置,方便后续进行部署。模型转换流程如下图所示。
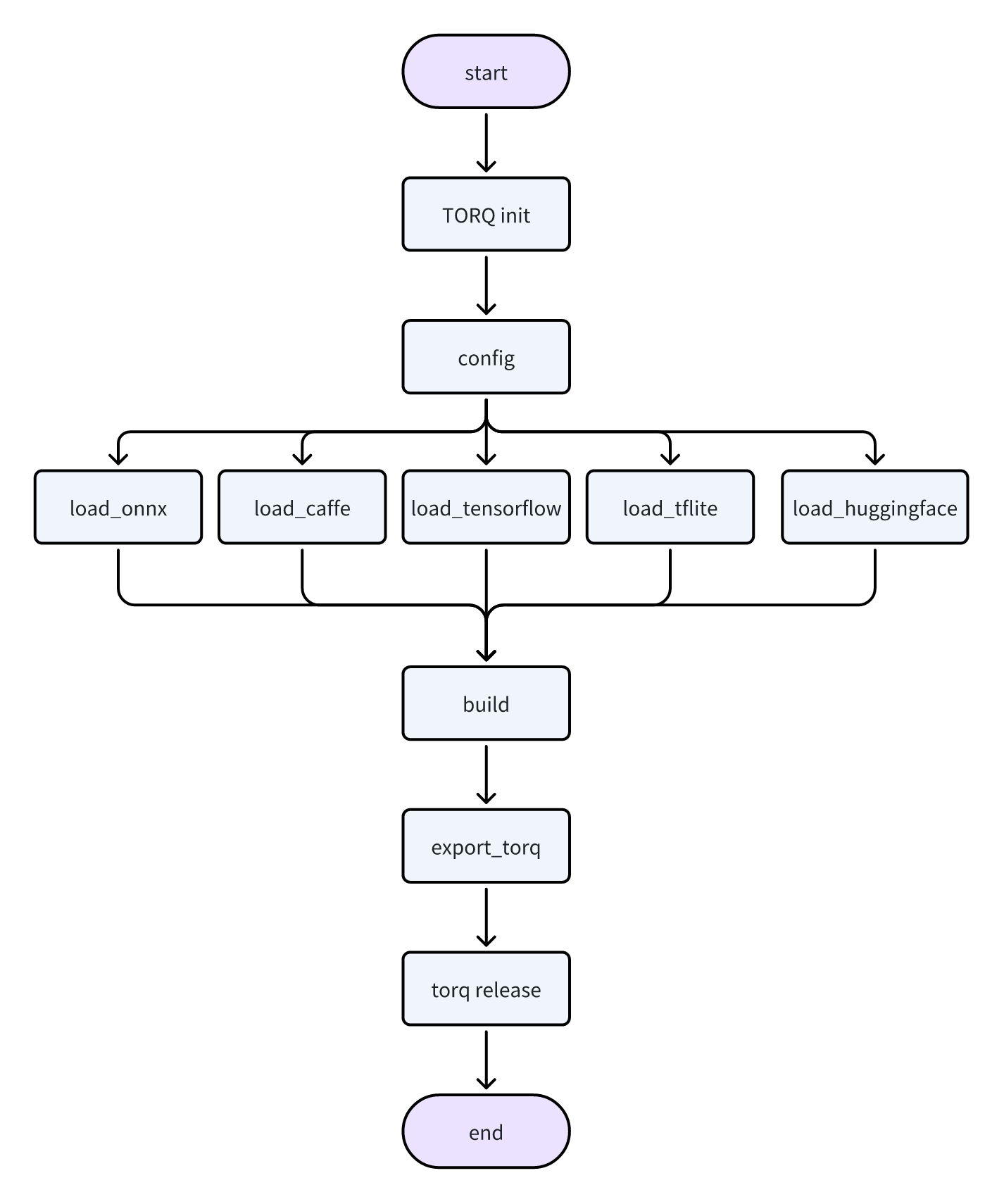
TORQ-Toolkit 模型转换支持的主流深度学习框架版本如下。
| 深度学习框架 | 支持版本 |
|---|---|
| Caffe | 1.0 |
| TensorFlow | 1.15 |
| TensorFlow Lite (TF Lite) | 2.4 |
| ONNX | 1.7.0~ 1.12.0 |
初始化 TORQ 对象
初始化 TORQ 对象。
接口函数
TORQ()
参数
| 参数 | 含义 |
|---|---|
| verbose | 控制是否打印详细日志(布尔值,默认 False)。 |
| verbose_file | 日志输出文件路径(仅当 verbose=True 时生效,日志将写入指定文件)。 |
示例代码
torq = TORQ(verbose=True, verbose_file="torq.log")
配置模型转换
用户可配置归一化参数、量化方法、目标平台,保证模型转换性能及效果。
接口函数
torq.config()
参数
以下列出部分常用配置参数,关于更多参数,请参考 TORQ-Toolkit API 参考。
| 参数 | 含义 |
|---|---|
| mean_values | 设置量化过程中输入的均值。 |
| std_values | 设置量化过程中输入的归一化值。 |
| target_platform | 指定 TORQ 模型的目标平台,支持 A200,A210。 |
| quantized_dtype | 指定量化类型,默认为w8a8。 |
说明: 设置
mean_values和std_values后,用户无需在板端 API 推理阶段进行均值和归一化操作,减少部署耗时。
示例代码
torq.config(mean_values=[[103.94, 116.78, 123.68]], std_values=[[58.82, 58.82, 58.82]], target_platform='a210')
加载模型接口
TORQ-Toolkit提供的模型加载接口支持 ONNX、Caffe、 TensorFlow、 TensorFlow Lite 等多种框架模型文件导入。用户可以根据不同框架的模型选择合适的接口进行加载,下面是各种框架的模型加载接口的简要介绍。
ONNX 模型加载接口(推荐)
加载 ONNX 模型。推荐使用ONNX模型。
说明: 加载前需确认 ONNX 模型文件(.onnx 后缀)路径。
接口函数
torq.load_onnx()
示例代码
# 从当前目录加载arcface模型
ret = torq.load_onnx(model='./arcface.onnx')
Huggingface 模型加载接口
加载 Huggingface 模型。
接口函数
torq.load_huggingface()
示例代码
# 从当前目录加载qwen0.5模型
ret = torq.load_huggingface(model='qwen0.5')
Caffe 模型加载接口
加载 Caffe 模型。
说明
- 加载前需确认 Caffe 模型文件( .prototxt 后缀)路径和权重文件( .caffemodel 后缀)路径。
- 如果模型有多个输入层,可以指定输入层名称的顺序。
接口函数
torq.load_caffe()
示例代码
# 从当前路径加载mobilenet_v2模型
ret = torq.load_caffe(model='./mobilenet_v2.prototxt', blobs='./mobilenet_v2.caffemodel')
TensorFlow 模型加载接口
加载 TensorFlow 模型。
说明: 加载前需确认 TensorFlow 模型文件( .pb 后缀)路径、输入节点名、输入节点的形状以及输出节点名。
接口函数
torq.load_tensorflow()
示例代码
# 从当前目录加载ssd_mobilenet_v1_coco_2017_11_17模型
ret = torq.load_tensorflow(tf_pb='./ssd_mobilenet_v1_coco_2017_11_17.pb', inputs=['Preprocessor/sub'], outputs= ['concat', 'concat_1'], input_size_list=[[1, 300, 300, 3]])
TensorFlow Lite 模型加载接口
加载 TensorFlow Lite 模型。
说明: 加载前需确认 TensorFlow Lite 模型文件(.tflite 后缀)路径。
接口函数
torq.load_tflite()
示例代码
# 从当前目录加载mobilenet_v1模型
ret = torq.load_tflite(model='./mobilenet_v1.tflite')
构建 TORQ 模型
构建 TORQ 模型。构建模型时,用户可以选择是否进行量化,�量化可以减小模型的大小和提高在 UCA 上的性能。
接口函数
torq.build()
参数
| 参数 | 含义 |
|---|---|
| do_quantization | 控制是否对模型进行量化,建议设置为 True 。 |
| dataset | 指定用于量化校准的数据集,数据集的格式是文本文件。dataset.txt 示例如下。 |
./imgs/ILSVRC2012_val_00000665.JPEG
./imgs/ILSVRC2012_val_00001123.JPEG
./imgs/ILSVRC2012_val_00001129.JPEG
./imgs/ILSVRC2012_val_00001284.JPEG
./imgs/ILSVRC2012_val_00003026.JPEG
./imgs/ILSVRC2012_val_00005276.JPEG
示例代码
ret = torq.build(do_quantization=True, dataset='./dataset.txt')
导出 TORQ 模型
导出 TORQ 模型文件( .torq 后缀),以便后续模型的部署。
接口函数
torq.export_torq()
参数
| 参数 | 含义 |
|---|---|
| export_path | 导出模型文件的路径。 |
示例代码
ret = torq.export_torq(export_path='./mobilenet_v1.torq')
释放 TORQ 对象
当完成所有的 TORQ 相关的操作后,用户需要释放TORQ 对象占用的资源。
接口函数
release()
示例代码
torq.release()
板端 C API 推理
本章节介绍通用 C API 接口的调用流程。
接口调用流程
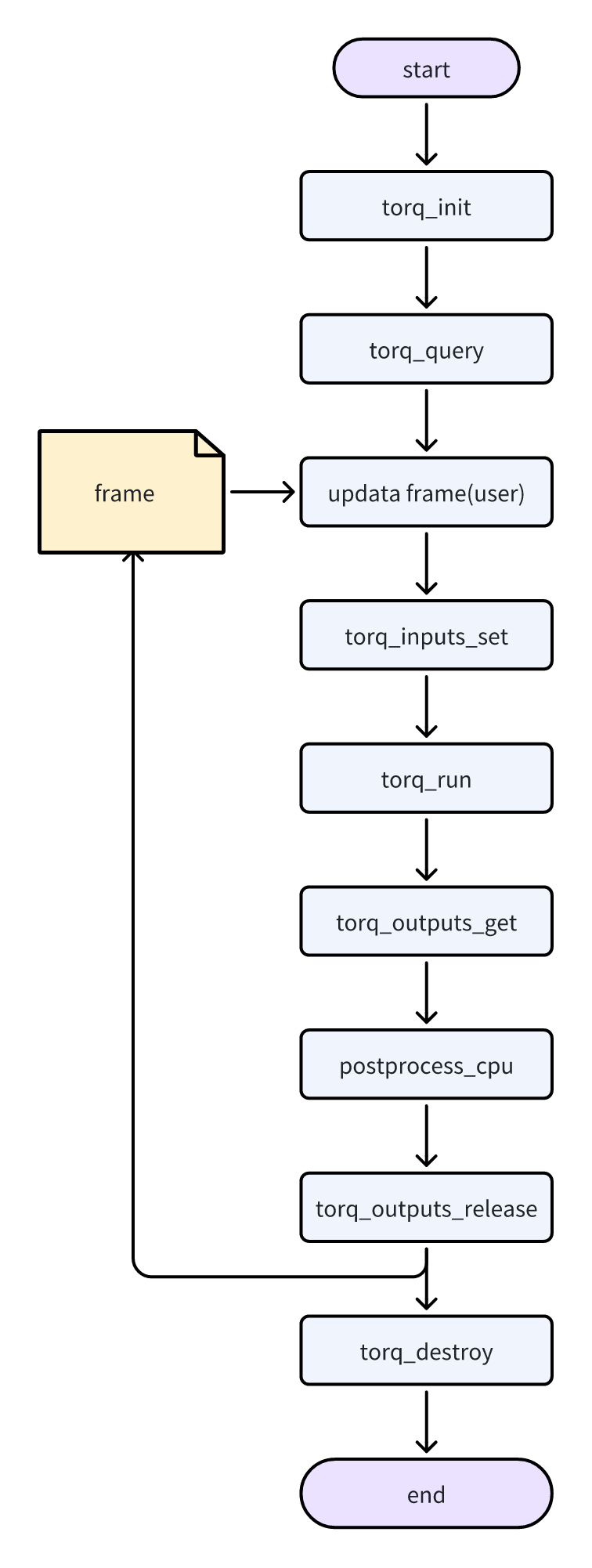
TORQ 通用 API 接口调用流程如下。
-
调用
torq_init()接口初始化模型。 -
调用
torq_query()接口查询模型的输入输出属性。 -
对输入进行前处理。
-
调用
torq_inputs_set()接口设置输入数据。 -
调用
torq_run()接口进行模型推理。 -
调用
torq_outputs_get()接口获取推理结果数据。 -
对输出进行后处理。
-
调用
torq_outputs_release()接口释放输出数据内存。 -
调用
torq_destroy()接口销毁 TORQ。
通用 API 调用流程如图所示。
示例代码
通用 API 调用流程如下。
// Init TORQ model
ret = torq_init(&ctx, model, model_len, 0, NULL);
// Get Model Input Output Number
torq_input_output_num io_num;
ret = torq_query(ctx, torq_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
// Get Model Input Info
torq_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++)
{
input_attrs[i].index = i;
ret = torq_query(ctx, torq_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(torq_tensor_attr));
}
// Get Model Output Info
torq_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++)
{
output_attrs[i].index = i;
ret = torq_query(ctx, torq_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(torq_tensor_attr));
}
torq_input inputs[io_num.n_input];
torq_output outputs[io_num.n_output];
memset(inputs, 0, sizeof(inputs));
memset(outputs, 0, sizeof(outputs));
// Pre-process
// Read Image
image_buffer_t src_image;
memset(&src_image, 0, sizeof(image_buffer_t));
ret = read_image(image_path, &src_image);
// Set Input Data
inputs[0].index = 0;
inputs[0].type = torq_TENSOR_UINT8;
inputs[0].fmt = torq_TENSOR_NHWC;
inputs[0].size = src_image.size;
inputs[0].buf = src_image.virt_addr;
ret = torq_inputs_set(torq_ctx, io_num.n_input, inputs);
// Run
ret = torq_run(torq_ctx, nullptr);
// Get Output Data
ret = torq_outputs_get(torq_ctx, io_num.n_output, outputs, NULL);
// Post-process
post_process(outputs, results);
// Release torq Output
torq_outputs_release(torq_ctx, io_num.n_output, outputs);
if (torq_ctx != 0)
{
torq_destroy(torq_ctx);
}
示例
TORQ 提供了不同模型的参考示例,包括 MobileNet 图像分类、 YOLOv5 目标检测等。关于 TORQ 示例,请参考 TORQ-Toolkit 快速上手。
说明: 不同平台、不同版本的工具和驱动程序可能会有略微不同的结果。